5.2. Parallelization
5.2.1. MPI Parallelization
5.2.1.1. Domain Decomposition
5.2.1.2. Cost Model
The weight associated with each cell used for load distribution using the RCB method is as follows:
with \(W_i\) the array of weights, i is the cell id, \(I_i\) the interactions in the cell i , \(P_i\) the number of particles in the cell i, \(N_i\) is the number of interactions, and F is the cost function associated to the interaction type.
Value |
Type |
F(Value) |
|---|---|---|
0 |
Vertex - Vertex |
1 |
1 |
Vertex - Edge |
3 |
2 |
Vertex - Face |
5 |
3 |
Edge - Edge |
4 |
4 |
Vertex - Cylinder |
1 |
5 |
Vertex - Surface |
1 |
6 |
Vertex - Ball |
1 |
7 |
Vertex - Vertex (RShape Driver) |
1 |
8 |
Vertex - Edge (RShape Driver) |
3 |
9 |
Vertex - Face (RShape Driver) |
5 |
10 |
Edge - Edge (RShape Driver) |
4 |
11 |
Vertex (RShape Driver) - Edge |
3 |
12 |
Vertex (RShape Driver) - Face |
5 |
5.2.2. Thread Parallelization
5.2.3. GPU Support
5.2.4. Benchmarks
5.2.4.1. Blade - CPU (Polyhedron)
Information:
Blade: {25,952 faces, 77,856 edges, 28,497 vertices}
Number of timesteps: 10,000
Number of polyhedra: 1,651,637
This benchmark is achieved by reproducing the tutorial simulation (Blade) with polyhedra 5 times smaller. See images below.
Test the hybrid parallelization
MPI + OpenMPMachine used: CCRT-IRENE with:
Node: bi-processor of skylake
Each processor has 24 cores
Frequency: 2.7GHz
until 16,384 cores

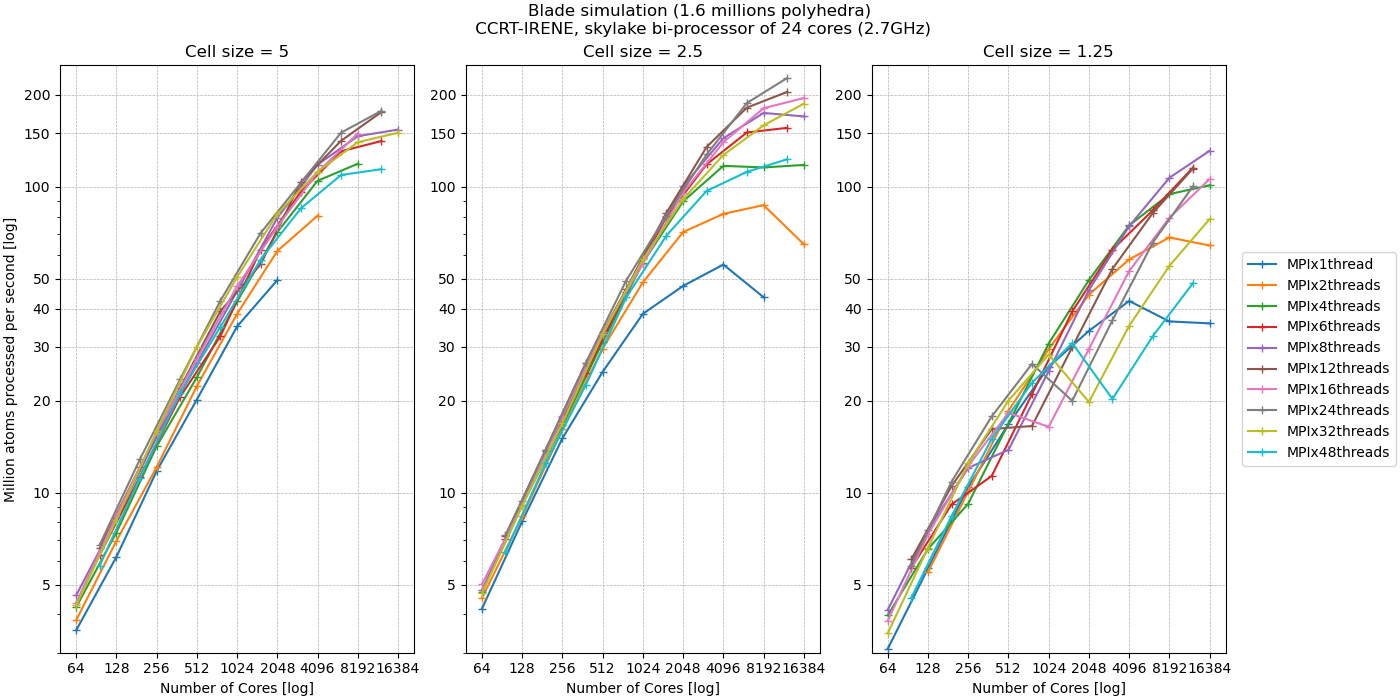
Some remarks:
For this test, the simulation domain is split into 39,000 cells and then distributed among the MPI processes. Some configurations fail because there are not enough cells per
MPIprocess.Best results are obtained with 24
OMPthreads per MPI process. This corresponds to the number of cores per socket. NUMA effects are likely to reduce performance beyond this.
5.2.4.2. Rotating Drum - GPU (Polyhedron)
This example is defined in the repository: https://github.com/Collab4exaNBody/exaDEM-benchmark/tree/main/rotating-drum-poly . This simulation is run on an a100 GPU using 32 cores. Result format: Loop time (Update Particles/Force Field).
Version |
Case 10k |
Case 80K |
|---|---|---|
v1.0.1 (06/24) |
28.1 ( 17.1 / 6.8) |
71.6 ( 37.8 / 26.0) |
v1.0.2 (11/24) |
23.3 ( 17.7 / 4.1) |
48.9 ( 33.0 / 13.8) |
master (05/12/24) |
6.38 ( 2.61 / 2.49) |
17.6 ( 11.65 / 4.3) |
v1.1.0 (27/03/25) |
6.99 ( 2.43 / 2.56) |
17.3 ( 10.94 / 4.4) |
v1.1.2 (22/07/25) |
10.4 ( 1.99 / 5.37) |
16.59 ( 9.35 / 4.2) |
v1.1.3 (01/09/25) |
10.77 ( 1.9 / 5.7) |
16.23 ( 9.0 / 4.1) |
v1.1.4 (24/09/25) |
8.36 ( 3.5 / 2.4) |
18.0 ( 10.8 / 4.1) |
v1.1.5 (26/10/25) |
8.44 ( 3.3 / 2.6) |
18.0 ( 10.8 / 4.1) |
5.2.4.3. Rotating Drum - CPU (Sphere)
This benchmark has been presented in 2023 within the paper [1] : “ExaNBody : a HPC framework for N-Body applications”.
Note
We are no longer able to reproduce this performance as the code has changed (hopefully for the better), but it shows the performance of the first prototype. The input files are no longer available either, as the operators have changed and the data structures have changed, notably with the improvements for interaction and parallelization per interaction instead of per particle in OpenMP/gpu.
Description:
Different OpenMP/Mpi configurations (number of cores/threads per mpi process) have been tested to balance multi-level parallelism.
Both simulations were instrumented during 1,000 representative iterations.
The performance of ExaDEM was evaluated using up to 256 cluster nodes, built on bi-socket 64-core AMD EPYC Milan 7763 processors running at 2.45 GHz and equipped with 256 GB of RAM.
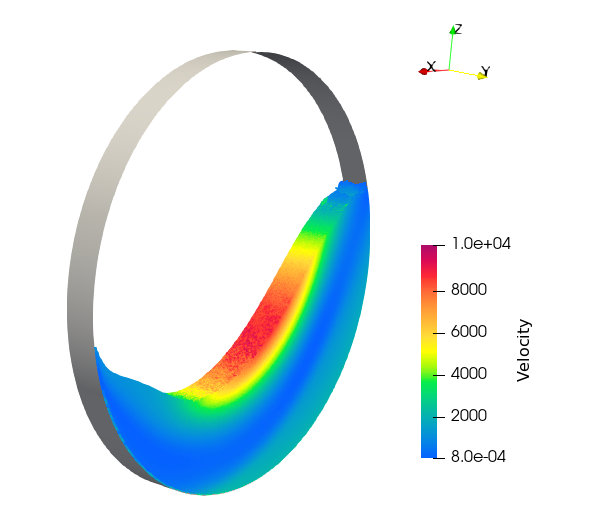
DEM simulation of 100 million spheres in a rotating drum.
ExaDEM’s performance is evaluated with a simulation of a rotating drum containing 100 million spherical particles, see the figure below.
This setup is a tough benchmark as particles are rapidly moving all around the heterogeneously dense domain due to gravity.
Additionally, the employed contact force model has a low arithmetic intensity, and exaDEM must handle pairwise friction information that is updated by kernel and must migrate between mpi processes when subdomains are redistributed.
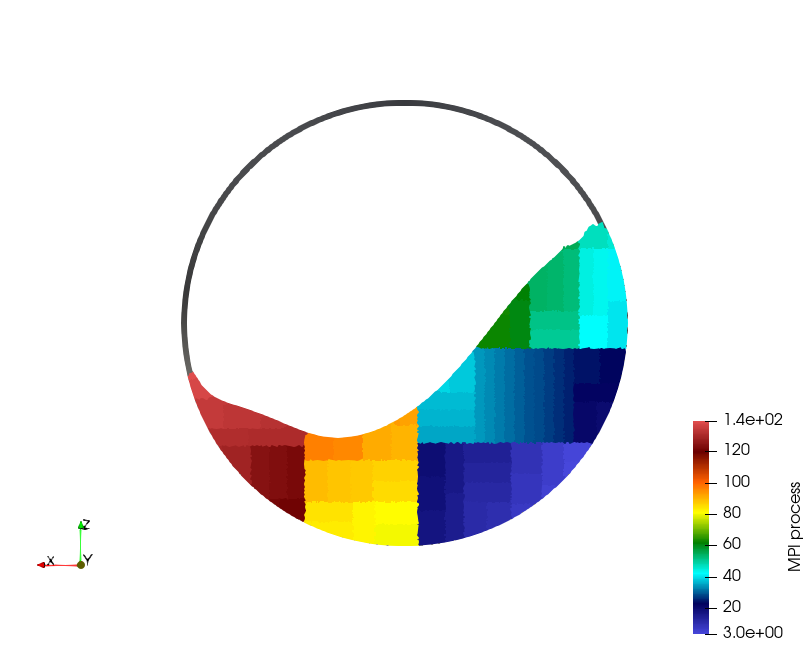
Domain decomposition of 100,000 spheres in a rotating drum
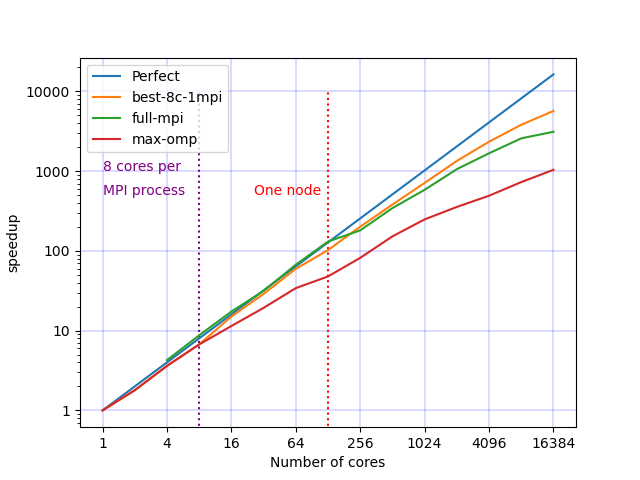
Speedup for different OpenMP/MPI configurations. ExaDEM simulation with 1, 8, and 128 threads per mpi process.
Note
Note that the Milan nodes are made up of 128 cores spread over 8 NUMA nodes, and we have pointed out that NUMA effects reduce overall performance.
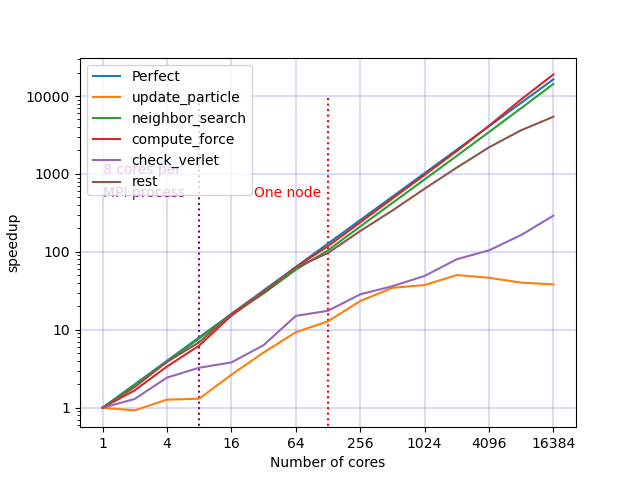
Operator speedup according to the total number of cores used.
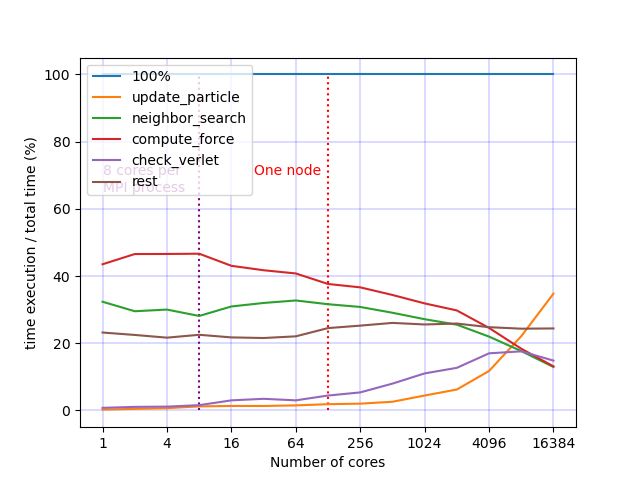
Operator time ratios at different parallelization scales.